Opened 9 years ago
Closed 9 years ago
#4460 closed defect (fixed)
ResolveLoops scales as O(N^3) in large linear circuit models
| Reported by: | Francesco Casella | Owned by: | Volker Waurich |
|---|---|---|---|
| Priority: | high | Milestone: | 1.12.0 |
| Component: | Backend | Version: | |
| Keywords: | Cc: |
Description (last modified by )
The ScalableTestSuite contains several models of electrical distribution systems, which lead to large algebraic loops made of linear equations.
For the largest examples, the execution time of resolveLoops scales as O(N3). For example, DistributionSystemModelica_N_XXX_M_XXX (whose number of equations is proportional to N*M) gives these figures
| N | M | Time [s] |
| 56 | 56 | 3.34 |
| 80 | 80 | 35.4 |
| 112 | 112 | 203.7 |
Given the sparsity pattern of the equations, which have only O(N) nonzero entries in the A-matrix, I'm not sure what is the theoretical complexity of the underlying algorithm. It may be O(N2), but it is probably not O(N3).
@vwaurich, please make sure that the implementation is efficient and does not introduce O(N) or O(N2) overhead.
If the algorithm has really O(N3) inherent complexity, then I would suggest to introduce an upper limit to the size of the systems which are subject to this type of analysis, as we have for tearing. As a default, I would suggest 5000 equations, which currently means about 1 s of processing time on these systems. Above this limit, the spent time quickly gets prohibitive and probably not worth the effort in most cases.
Attachments (1)
{kind=link}
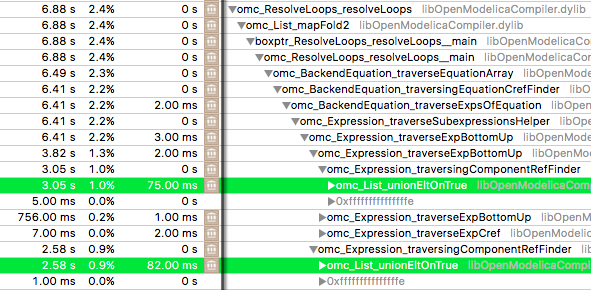{kind=link}
Change History (6)
comment:1 by , 9 years ago
| Description: | modified (diff) |
|---|
by , 9 years ago
| Attachment: | Bildschirmfoto 2017-07-13 um 15.14.58.png added |
|---|
comment:2 by , 9 years ago
follow-up: 5 comment:3 by , 9 years ago
I have rewritten the critical part of ResolveLoops.
Results on my machine are:
| N=M | time |
|---|---|
| 40 | 0.244 |
| 56 | 0.516 |
| 80 | 1.702 |
| 112 | 2.538 |
comment:4 by , 9 years ago
Sounds good. I've started a run on Hudson, will close the ticket afterwards.
comment:5 by , 9 years ago
| Resolution: | → fixed |
|---|---|
| Status: | new → closed |
Replying to vwaurich:
Results on my machine are:
N=M time 40 0.244 56 0.516 80 1.702 112 2.538
The results on Hudson are
| N=M | time |
|---|---|
| 40 | 0.250 |
| 56 | 0.340 |
| 80 | 0.876 |
| 112 | 3.172 |
The step from 80 to 112 (2X size) is 4X, which hints to O(N2), but on the other hand from 56 to 112 (2X size) it is 8 times, which is only slightly superlinear. In any case, we have a drastic reduction in time compared to the previous situation (70X faster on the larger model), so this is no longer the bottleneck in the backend by far and large.
Time eater is a call to List.unionEltOnTrue(). See attached screen shot of profiler. This is a run for N=M=56